I spend the weekend trying to combine these two threads. The main motivation is to understand whether we can achieve a lift on model capability ✨ for free ✨ when facing a data-constraint setting. The authors estimated that talkie was trained only on 260B tokens. For simplicity, I;m also starting with reasoning. For example, can we get talkie to be a bit more efficient/better on HumanEval?
The goal is not benchmark-maxxing, as talkie has much better uses :) We just want to validate the idea.
For convenience, our corpora pull from Project Gutenberg, period-appropriate books that talkie has likely already seen in pretraining. We start with arithmetic, and later add logic and science to test breadth:
- 1894, First Steps in Algebra, Wentworth (arithmetic)
- 1830, Elements of Arithmetic, De Morgan (arithmetic)
- 1896, Symbolic Logic, Carroll (logic)
- 1861, The Chemical History of a Candle, Faraday (science)
Recipe: Self-Play In Corpus Environments (SPICE)
SPICE proposes a generalizable recipe that cleverly leverages the data. Specifically, the model conditions on a passage to synthesize its own (question, answer, gold) pairs, which it then reason about during a second forward pass. As Challenger it reads a document and writes a question with a gold answer. As Reasoner it then tries to answer that question without seeing the document. The same weights train on both jobs at once.
This is an ordinary policy-gradient setup. The base model is our policy $\pi_\theta$, and we maximize its expected reward $J(\theta)$ by gradient ascent on the weights $\theta$. $J$ adds the reward the model earns as Challenger and as Reasoner, averaged over the corpus.
\[J(\theta) = \mathbb{E}_{d \sim D}\Big[\, \underbrace{\mathbb{E}_{(q,a^*)\sim \pi_\theta(\cdot\mid d,\,C)}\big[r_C\big]}_{\text{Challenger}} \;+\; \underbrace{\mathbb{E}_{\hat a \sim \pi_\theta(\cdot\mid q,\,R)}\big[r_R\big]}_{\text{Reasoner}} \,\Big]\]We draw a document $d$ from the corpus $D$. From that document the Challenger writes a question and gold pair $(q, a^*)$ and earns $r_C$. The Reasoner then answers the question and earns $r_R$. We want weights that make both terms large.
The Reasoner reward is the easy one. It is one when the answer matches the gold and zero otherwise.
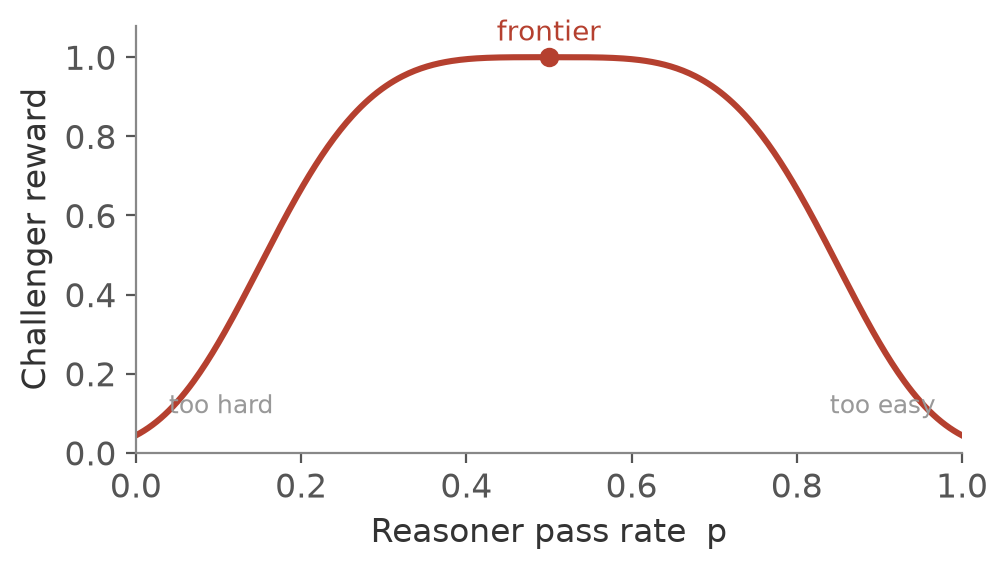
\[r_R = \mathbb{1}[\hat a = a^*]\]The Challenger reward drives a the core idea. We do not incentivize questions that are too easy nor too hard. The objective encourages question generation that lands right at the Reasoner’s edge. To find that edge, we let the Reasoner answer the same question $k$ times and mark each attempt right or wrong. Let $p$ be the fraction of those $k$ attempts that were correct. The spread of a yes or no outcome is its variance, $p(1-p)$. That spread is zero when the Reasoner gets the question every time ($p=1$) or never ($p=0$), and it is largest when the attempts split in half ($p=0.5$), where the variance equals $0.25$.
So the Challenger reward is a bump centered on that halfway point!
\[r_C = \exp\!\left(-\frac{\big(\,p(1-p) - 0.25\,\big)^2}{2\sigma^2}\right)\]It is a Gaussian on the variance, equal to one at $p=0.5$. The width $\sigma$, a hyperparameter, sets how sharp the peak is ($\sigma^2 = 0.01$ in SPICE). Therefore, falloff can be steep:
- 4/8 split rewards 1
- 6/8 rewards 0
- 7/8 rewards 0.37
- 8/8 rewards 0.04 (close to nothing)
Finally, we turn our reward into a gradient. Here, SPICE follows group policy by subtracting the baseline from the average reward of the group, and call the result the advantage.
\[\hat A_i = r_i - \frac{1}{N}\sum_j r_j\]The policy gradient then nudges the model to make each sampled response more likely in proportion to its advantage,
\[\nabla_\theta J = \mathbb{E}\big[\,\hat A_i \,\nabla_\theta \log \pi_\theta(\text{response}_i)\,\big]\]The DrGRPO advantage is to be distinguished from vanilla GRPO. GRPO divides the advantage by the group’s standard deviation, which quietly biases training toward low-variance prompts. “GRPO done right” drops that normalization and keeps the plain mean-subtracted form. Importantly, we also center inside each role, Challenger against other Challengers and Reasoner against other Reasoners, since pooling the two would blur the comparison.
Here are some talkie outputs:
To help the model, we prompt the model with few-shot samples (varied per train corpus). The task is intentionall simplfied to Yes/No/TBD. This is not terribly interesting, is hopefully within model capability. Here, the multiple-choice question format is followed, and the CoT is solid. However, there are two nuances that could be better: 1. Not terribly interesting, and 2. The question itself is not self-contained, meaning the Reasoner cannot solve it reasonably without the passage.
Results
Before the ablations dig in, the short version. On this data-constrained vintage model, corpus-grounded self-play does buy a real capability lift, and close to for free. Held-out arithmetic climbs over training and holds in the 0.6 to 0.7 range, up from around 0.4 to 0.5 at the start.
A handful of evals, step 0 of the run against its last step, locates the gain.
| Eval task | step 0 | step n |
|---|---|---|
| Arithmetic free form (in distribution) | 0.40 | 0.70 |
| Arithmetic ranked classification (in distribution) | 0.53 | 0.72 |
| Morse decode (near transfer) | — | — |
| HumanEval pass@1 (far transfer) | — | — |
| HumanEval pass@5 (far transfer) | 0.11 | 0.11 |
The two in-distribution rows move while near and far transfer stay flat, which is what a narrow loop on a weak model should do. It sharpens the trained skill without spilling into general reasoning.
You can watch the loop that earns it. The two roles stay in tension the whole way, the Challenger reward holding its mid band while the Reasoner reward and frontier rate sit near a half rather than running to zero or one.
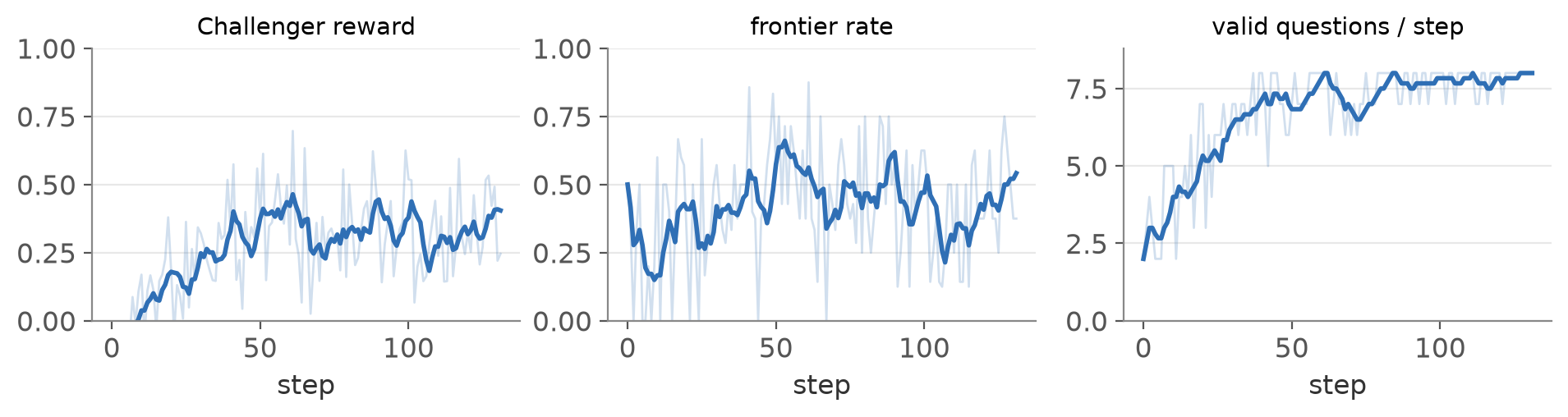
Two conditions decide whether that happens. The reward has to be verifiable. With computed gold the eval climbs, but when the model grades its own answers it collapses to about 0.3. And the lift stays in-band. Arithmetic improves while HumanEval and MMLU never move, so this is a gain on the trained skill, not on general reasoning.
The ablations below pin down each piece: where the gain comes from, what does not matter, and where the loop breaks.
Ablation: Is groundtruth required for SPICE?
Since our chosen datasets might come with groundtruth (eg. Math textbooks) and self-computed gold (eg. simple arithmetics), we run a quick ablation to compare computed gold against self-generated gold, where the Challenger writes its own key.
When the Challenger wrote its own key, the key was right only 11% of the time, and 73% of the tasks it called agreed were wrong. The errors were not random. They sat on the two things the model fails at, distributing over parentheses and signs on negative results. The Challenger states a wrong answer, the Reasoner shares the same blind spot and agrees, $p$ goes to one, and the wrong value trains as the gold. A model cannot correct a mistake that both of its halves make.
Both halves drop the parentheses to 6 × 4 and agree on 24, so the wrong value trains as the gold. The true answer 36 never appears.
With computed gold none of this happens, because the key is never invented.
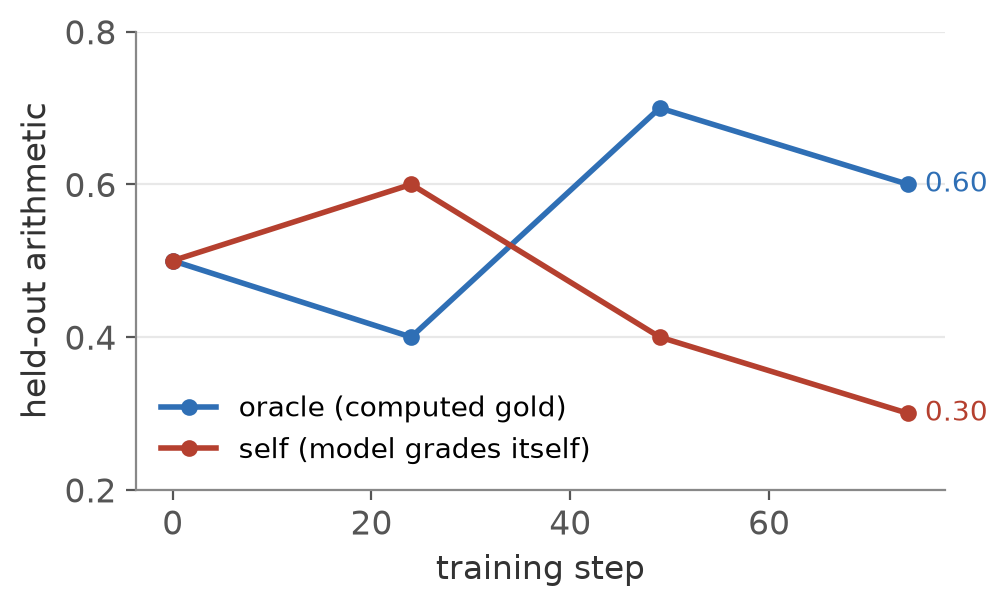
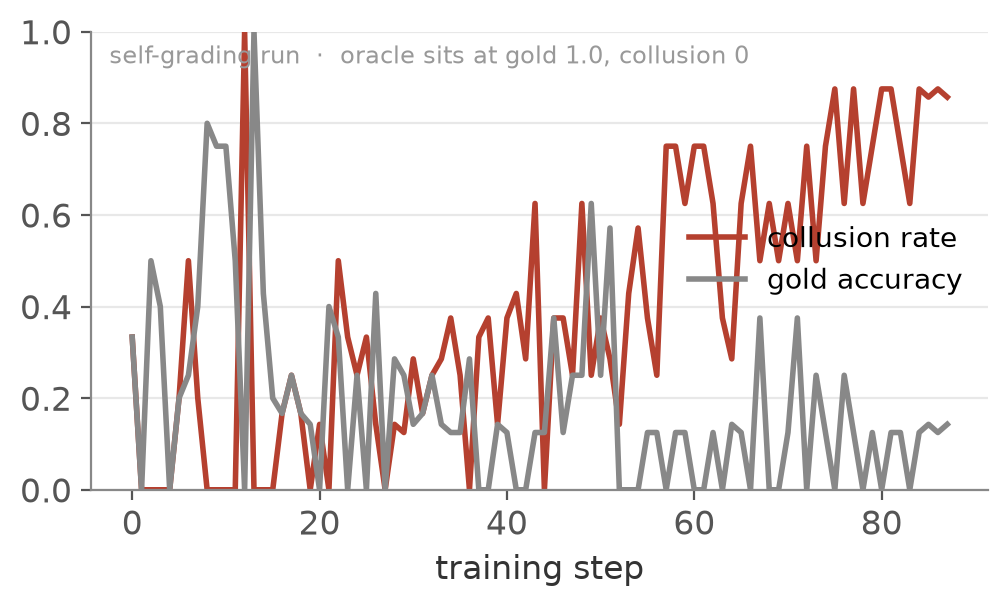
The eval is the symptom, and the training signal shows the cause. Held-out arithmetic holds around 0.60 under computed gold and slides to 0.30 under self grading (left). Meanwhile the self-written key is right only about a tenth of the time, and the share of tasks where both halves agree on a wrong answer climbs past 0.7 (right). At the model’s current level, the oracle is not a luxury.
Ablation: Does the advantage form matter?
Both forms reduce the Reasoner to a single number $p$, its chance of answering correctly, which feeds both the variance reward and the Reasoner’s own advantage. They differ only in how $p$ is obtained.
The rollout form samples $k$ answers and counts the hits, a Monte Carlo estimate:
\[p_{\text{rollout}} = \frac{1}{k}\sum_{i=1}^{k}\mathbb{1}[\hat a_i = a^*], \qquad \hat a_i \sim \pi_\theta(\cdot \mid q)\]correct_prob_norm skips the sampling. For a multiple-choice question it scores each option by its length-normalized log-likelihood and takes the softmax mass on the gold option:
\[p_{\text{cpn}} = \frac{e^{\ell(a^*)}}{\sum_{o}\, e^{\ell(o)}}, \qquad \ell(o) = \frac{1}{|o|}\log \pi_\theta(o \mid q)\]It is the noiseless version of the same pass rate, the exact probability rather than a $k$-sample estimate of it.
No measurable difference. Both trained the loop the same way. The honest reason is that the comparison barely had room to show, since the model chose multiple choice only about 15% of the time and answered the rest free form, so the two scorers rarely disagreed. We log it as a null rather than a win for either.
Reward hacks
Self-play did discover a few paths of least resistance.
For instance, it learned to leak the answer into the question. Asked for an open task it would write something like “what is 7 plus 4, that is 11,” so the Reasoner only had to copy. We gate this by checking that the answer does not already sit in the question.
When we relaxed the match to accept free text, hoping to admit softer questions, it found the cleanest exploit of all. It made the question and the answer nearly identical, so any overlap check fired at $p$ equal to one.
From the free text run. The answer just restates the question, so the matcher always passes.
This eventually collapsed the model and dropped HumanEval to 0.036. Any low entropy answer spacealso invites the same trick. Yes or no, and a bare “(A),” both got gamed, since a guess lands often enough to look like skill. We verify the gold against the source and shuffle the option positions.
Interestingly, SPICE contains a built-in reward hack prevention where, under the variance reward, copying the answer drives $p$ to one, and one sits at the bottom of the reward rather than the top.
Scaling self-play with self-guidance
The last question is the tempting one. Drop the oracle, let the model generate and grade and answer across many corpora, and hope breadth carries it. We pooled two more period books with the arithmetic pair, Lewis Carroll’s Symbolic Logic and Faraday’s Chemical History of a Candle.
The questions it wrote were often a delight. Reading those passages, talkie composed its own Carroll-style syllogisms (Example #1) and even candle chemistry, answered in the same register.
From Faraday's candle lectures, answered without the passage.
The trouble was never the questions. It was the grading. A single arithmetic corpus under self grading already colludes about 73% of the time. Pool the four and that climbs to 0.99, the model agreeing with itself on nearly every wrong answer. Capability went with it and HumanEval fell from 0.107 to 0.036. More surface to hide in is not more signal.
You can watch the loop give up over training. Early on the Challenger reaches for two step problems and misses. Later it has retreated to single steps it can ace, which pays nothing and teaches nothing.
The curriculum backed away from hard questions rather than climbing toward them, the opposite of what the variance reward intends.
A frozen base as the answer key
If the problem is a corrupt answer key, fix the key, not the student. The cheap fix that imports no outside teacher is the model’s own untrained base. Before a task is allowed to count, the frozen base, the LoRA adapter switched off so it costs no extra weights, has to agree with the gold the policy wrote. A KL leash would not help here. Two policies a short distance apart still collude, because the base shares the blind spot, and a global leash would also strangle the arithmetic gains we run at β=0 to keep. The gate only filters drift, the part of collusion that runs away. Blind spots the base already has slip through, but those are bounded at the base error rate while drift is what compounds to 0.99.
It worked on the failure it was built for. Across 394 steps the agreement-on-wrong-answers rate sat near 0.05 to 0.14 and fell as training went on rather than climbing to 0.99. Self-written gold went from about two thirds correct to nineteen in twenty.
And then the loop went quiet. The fraction of questions landing at the frontier all but emptied, and the collusion rate fell not because the blind spot healed but because the questions got trivial. Late in training the Challenger is asking what is six times five, and the base, the policy and the gold all agree it is thirty.
The gate killed the runaway, then the curriculum retreated to questions everyone could ace. Self-guidance buys safety, not capability.
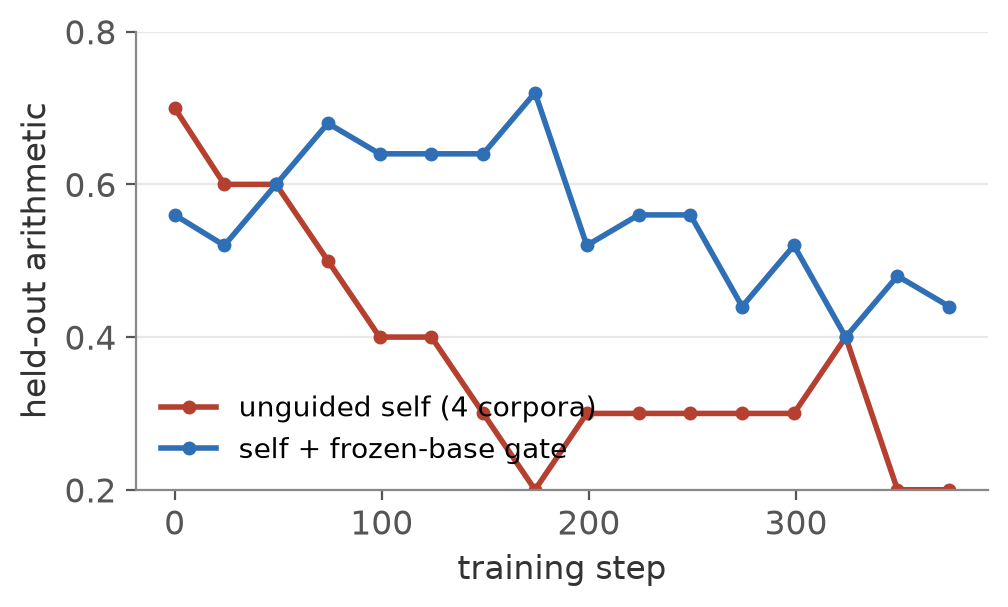
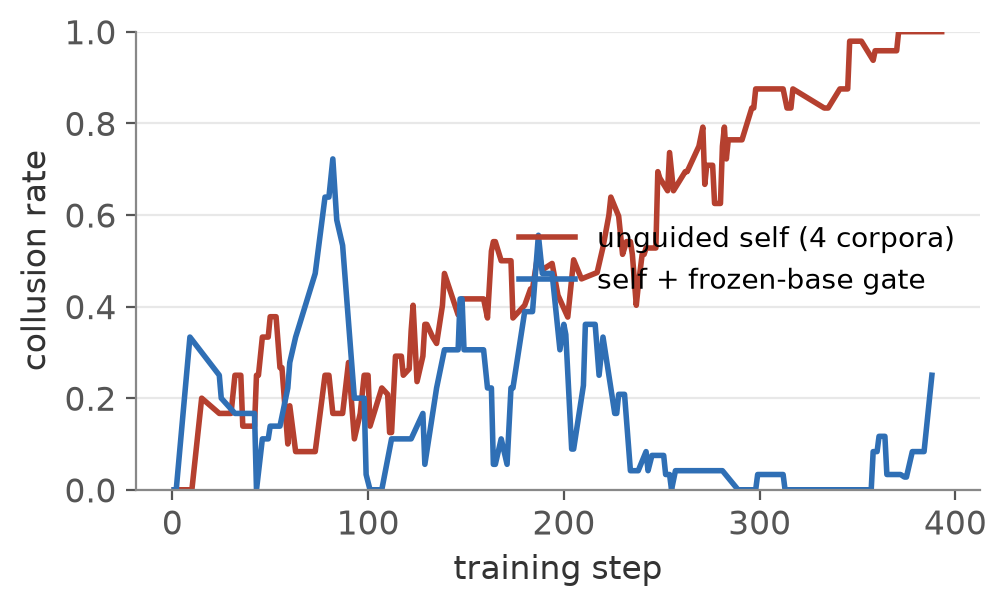
So the gate does what it promises and no more. It removes the runaway, but it cannot push difficulty upward, and a weak model with nothing pulling the frontier higher drifts to the easy questions it already knows. That is the same ceiling as everywhere else in this post. Capability came only from a key the model could not write for itself.
References
- SPICE: Self-Play In Corpus Environments. arXiv:2510.24684
- Absolute Zero: Reinforced Self-play Reasoning with Zero Data. arXiv:2505.03335
- Understanding R1-Zero-Like Training (Dr. GRPO). arXiv:2503.20783
- Stanford paper. arXiv:2604.20209
- talkie. talkie-lm.com
- Are vintage LLMs the start of a new kind of history? Res Obscura
{kind=link}
{kind=link}
{kind=link}